来源 | PaperWeekly
继续探索 Graph OOD 的相关问题,与以往工作不同的是,这篇工作避开了复杂的数学推导和琐碎的数据生成过程,直接从简单有效的判别模型入手研究图上的 OOD 检测问题。

论文题目:
Energy-based Out-of-Distribution Detection for Graph Neural Networks
论文链接:
https://arxiv.org/abs/2302.02914
代码链接(含实验细节说明):
https://github.com/qitianwu/GraphOOD-GNNSafe
尽管针对图数据的学习方法目前已取得了空前的进展,绝大部分现有的方法都假设训练数据与测试数据来自同一分布。目前有大量研究表明,现有的图深度学习模型(如图神经网络)通常在分布外数据上表现差强人意,这也使得针对图数据分布外泛化(Out-of-Distribution Generalization,简称 OOD 泛化)问题的研究 [1,2] 逐渐流行起来。
OOD 泛化问题旨在解决训练和测试分布不一致的问题,其学习目标是为了提升模型在新的未知分布的测试数据上的性能。而另一类比较常见的实际问题,是分布外检测(Out-of-Distribution Generalization Detection)[3,4],问题定义为:
当分类器在有限观测的训练数据上完成训练后,需要具备识别测试集中不同于训练主体分布的数据(即 OOD 数据)的能力。
尽管 OOD 检测在图像领域已被广泛研究,但针对图数据的分布外检测还是一个几乎未被探索的领域 [5]。
01.图上节点分布外检测的问题定义
首先,从整体上看,与图片不同的是,图结构数据中的每个样本通常是图上的节点。由于节点互联的特性,节点样本之间存在着依赖关系,导致了样本的非独立性。因此,在对 OOD 样本进行判定时,需要考虑到这种数据依赖关系(data inter-dependence)。
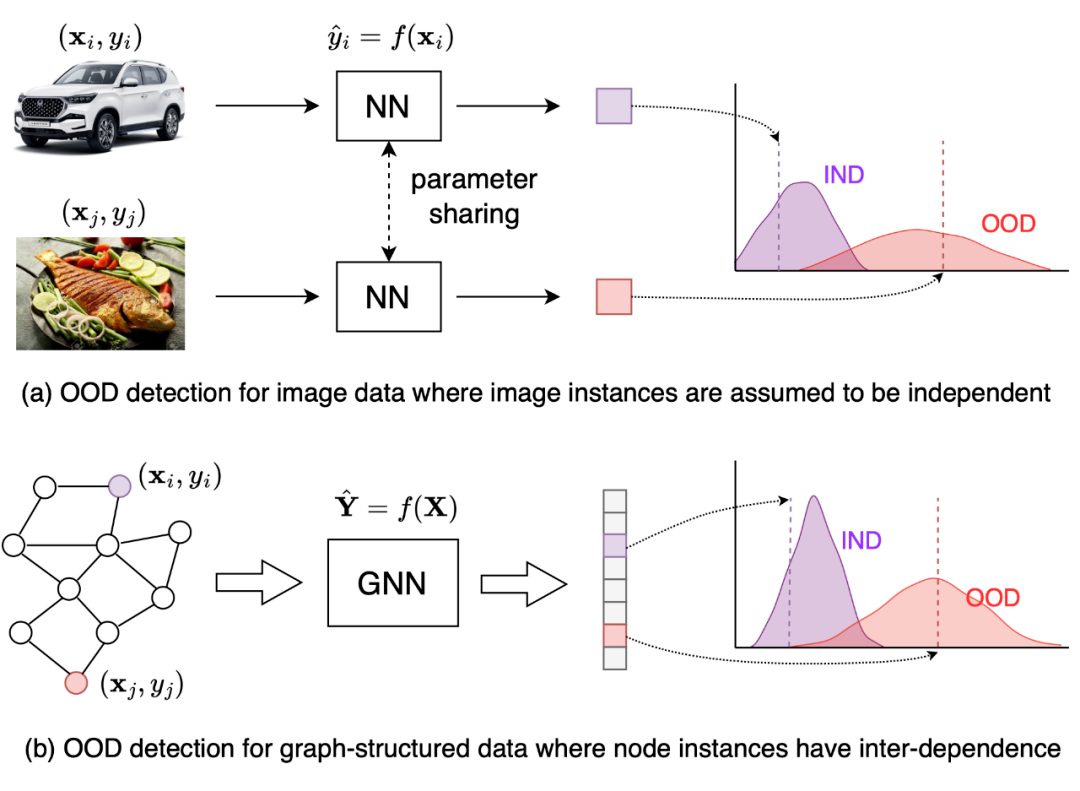
▲ 图片样本分布外检测与图中节点分布外检测的对比。图片数据可以看作i.i.d.产生的独立样本,而图中的节点样本存在互相的依赖关系。
下面我们对图上的 OOD 检测问题给出定义。假设输入数据样本构成了一个图 , 是节点集合, 是连边集合,使用 表示邻接矩阵。图中每个节点 都是一个样本,包含输入特征 和标签 。
图中的节点集合 分成了训练集 和测试集 。定义 和 ,我们需要训练一个节点分类器 ,它能预测节点的标签 。此外,更重要的是,这一分类器具备识别分布外样本的能力。具体的,考虑一个由 产生的决策函数 ,使得对于任意输入 有:
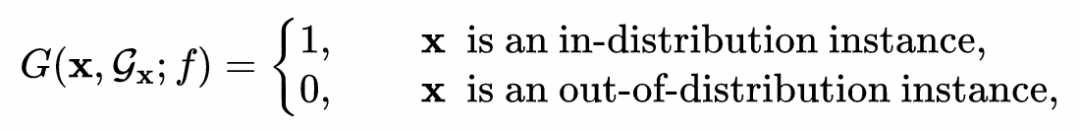
其中 表示节点 在图中对应的邻居子图。
02.基于能量模型的节点OOD检测
本文提出的方法主要基于简单有效的设计原则。首先,对于输入图首先考虑一个图神经网络 来得到节点的表征。具体的,如果采用图卷积网络(GCN),其节点表征的更新公式如下:

在上式中节点表征的计算依赖于图中相邻的节点,从而将样本间的依赖关系建模了出来。通过 层图卷积之后,将最后一层的输出结果 作为 logits 用于对节点标签的预测,即模型给出的预测分布可以写为:
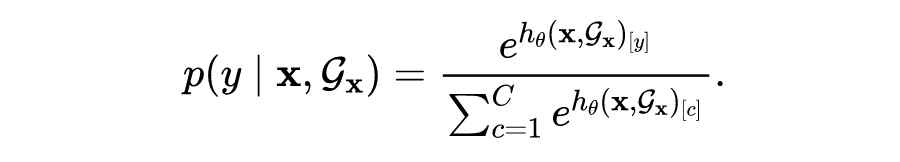
用于 OOD 检测的能量函数
已有的研究[6]表明,当假设 时,上式可以看作一个玻尔兹曼分布(Boltzmann distribution):
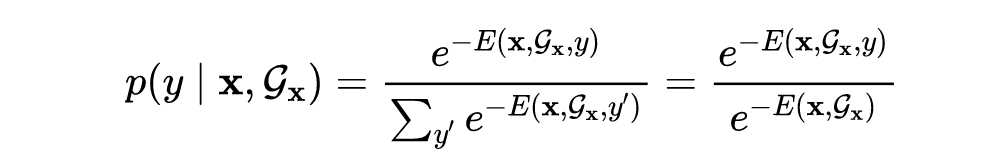
这里的 称为分类器 对应的给定标签 下的能量函数,而通过对 进行 marginalization 可以得到对于输入 的自由能量函数:
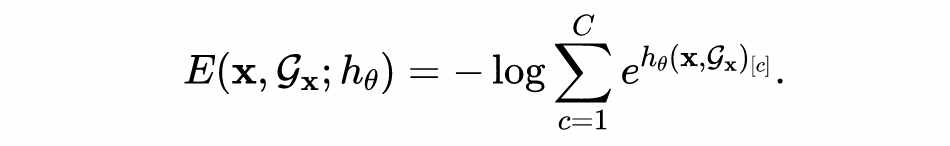
这一能量函数对每个输入节点都能返回一个能量值,它可以衡量分类器对图中节点的置信度,即作为判别是否是 OOD 样本的依据。
基于能量的信任传播
为了进一步的利用图结构产生的样本依赖性,我们提出了基于能量的信任传播,具体实现为将每个节点的能量值沿着输入图进行信息传递:
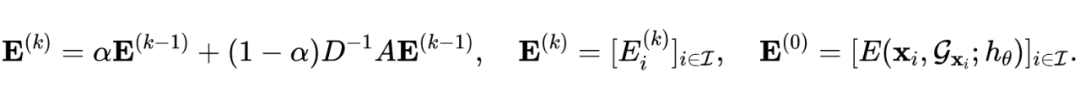
这样做的好处是,可以使得分类器产生的置信度沿着图结构加强。由于图中相邻的节点通常可以看作来自相似的数据分布,当我们聚合相邻节点的能量值后得到的新能量值 就更容易区分出来自不同分布的节点。我们在论文的3.2节也对这一结论给出了理论证明,并且在实验中通过大量的消融实验验证了这一简单方法的有效性。
损失函数
在模型训练方面,我们考虑两种可能的情形,以分别适用于两种被广泛研究的 OOD 检测问题。第一种情形是训练集中仅包含主体分布数据(即分布内训练数据 ),此时可以使用标准的分类损失函数训练图神经网络分类器(我们称提出的方法叫 GNNSafe):

另一种情形是训练数据中还额外包括已知的分布外数据(表示为 ),此时常见方法是引入一个额外的正则项,例如可以对模型输出的能量值进行上下界约束 [7](我们称提出的方法叫 GNNSafe++):
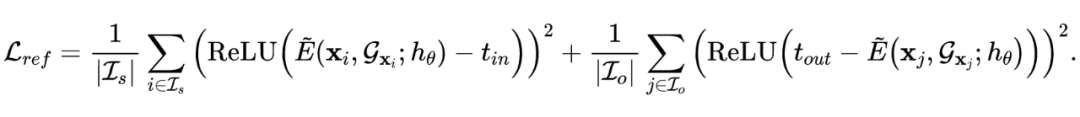
对于第二种情形最终的损失函数可以写为加权和 。
03.评测标准与实验结果
由于图数据的分布外检测问题目前还有待探索,本文也对这一问题背景下如何有效和全面的评测模型的能力给出了系统的探讨,包括1)如何选择数据集,2)如何划分数据集,3)如何评估 OOD 检测的能力。
评估准则
首先,需要明确的是,与传统监督学习不同的是,OOD检测问题需要额外考虑分布外的测试数据(以及可能用到的训练数据)。下图展示了监督学习与OOD检测(包含两类问题)问题对数据集划分的要求。
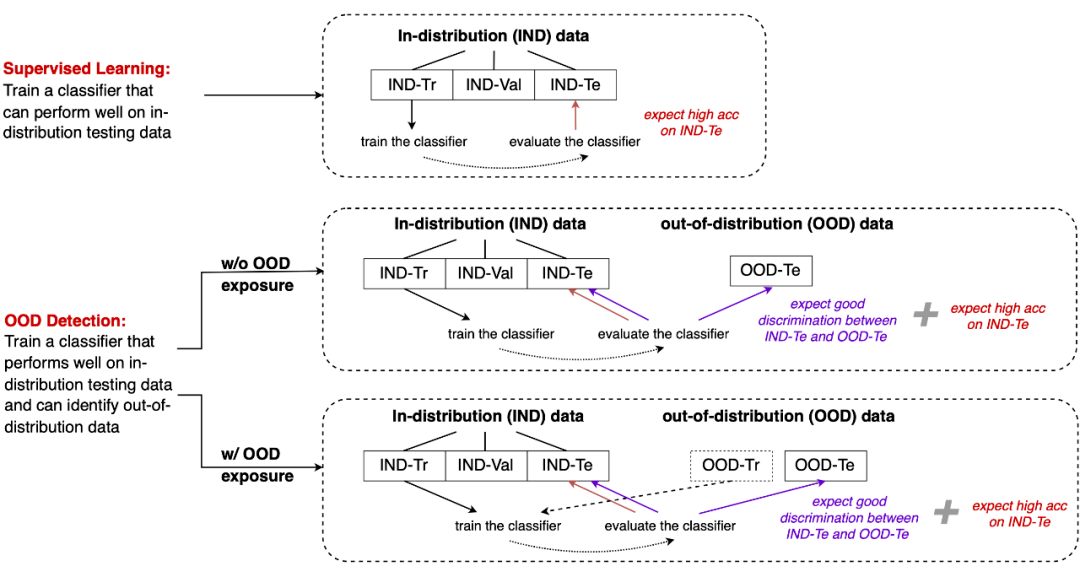
▲ 传统监督学习与分布外检测问题(包括两类情形)的直观对比。这里 IND-Tr/IND-Val/IND-Te 表示从主体数据(in-distribution data)中划分得到的训练/验证/测试集。OOD-Te 表示与主体数据来自不同分布的测试集,而 OOD-Tr 表示与主体数据来自不同分布的训练集。
监督学习(对应上图分支1):对数据集划分为训练/验证/测试集,模型在训练集上训练,而后在测试集上评估预测性能。为了区分,我们称这里的数据为分布内数据(in-distribution data,简称 IND),它被进一步划分为 IND-Tr/IND-Val/IND-Te。
OOD 检测(对应上图分支2):与监督学习相同的是,模型训练依然基于 IND-Tr 数据,但在测试阶段,模型除了要在 IND-Te 给出不错的预测精度,还要能有效区分 IND-Te 与分布外测试数据(简称 OOD-Te)。
带 OOD exposure 的 OOD 检测(对应上图分支3):与前一种情况不同的是,模型训练阶段还能利用额外的分布外训练数据(简称 OOD-Tr)。
数据集和划分
数据划分是非常重要的环节,需要考虑的是如何在不破坏原数据内在特性的情况下,引入分布差异。整体原则包含两点:
原则1:IND 和 OOD 数据需要来自不同的分布。特别的,OOD-Tr 和 OOD-Te 也通常需要来自不同分布
原则2:IND-Tr/IND-Val/IND-Te 数据需要来自同样的分布。
基于上述两个原则,我们进一步考虑两类常见的图数据集,对数据的划分方式描述如下图。

▲ 两种典型的图数据集(多图与单一图)与分布划分的评测标准。对于多图数据集,将一个图中的所有节点视为来自同一分布,用图来划分数据的分布。对于单图数据集,利用节点的 context 信息(例如时间、地点)来划分数据的分布。
具体的,我们在实验里考虑了五个不同的数据集,根据它们不同的特性,采用不同的划分方式:
Twitch(多图数据集):包含多张图,使用图 DE 作为 IND(并进一步按 1:1:8 随机划分为 IND-Tr/IND-Val/IND-Te),使用图 EN 作为 OOD-Tr,其余的图 ES, FR, RU 作为 OOD-Te
Arxiv(单图数据集,节点含 context 信息):使用节点的时间信息来划分 IND/OOD-Tr/OOD-Te,同样对于 IND 进一步按 1:1:8 随机划分为 IND-Tr/IND-Val/IND-Te
Cora/Amazon-Photo/Coauthor-CS(单图数据集,节点不含 context 信息):对于这类数据集不含已知的 domain 信息,我们人为的引入分布差异。具体的,使用原图作为 IND(进一步按 1:1:8 随机划分为 IND-Tr/IND-Val/IND-Te),而后对原图进行变换得到 OOD-Tr 和 OOD-Te。考虑三种变换:
● 结构干预:利用随机块模型生成图结构,替换原始输入图结构
● 特征内插:利用随机配对的节点的特征的线性加权和替换原始节点特征
● 标签保留:利用标签类别进行划分
实验结果
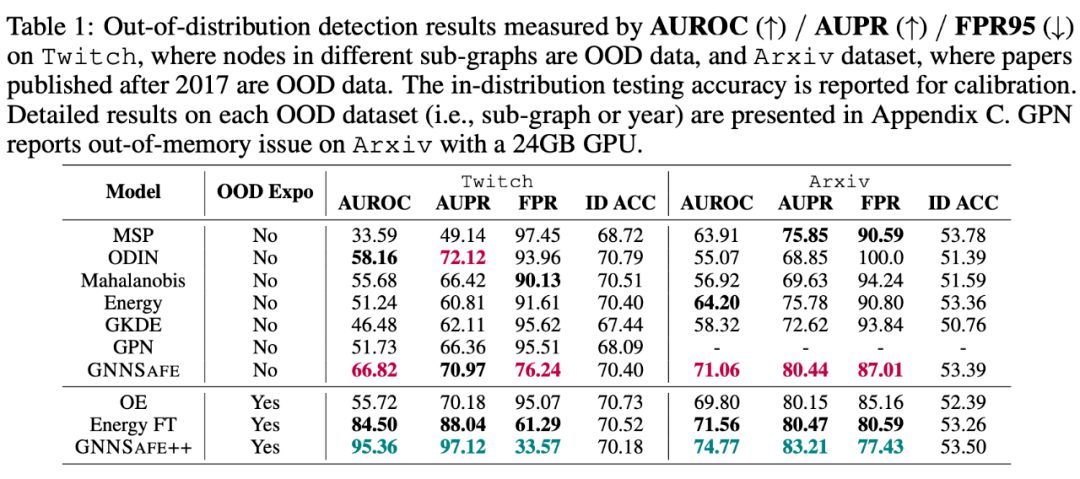
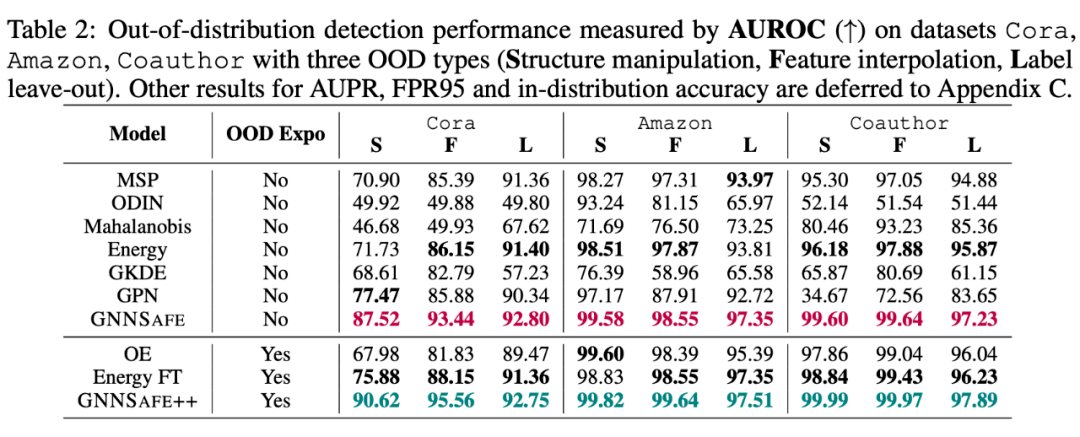
下面的表格展示了在 5 个数据集上的 OOD detection 结果,这里采用常规的评测指标 AUROC/AUPR/FPR95 来衡量模型对 IND-Te 和 OOD-Te 样本估计值排序的正确性。这里我们统一使用 GCN 作为分类器主干,并在两种情形下进行各自的对比,即使用或不使用 OOD exposure。
可以看到,本文提出的方法 GNNSafe 显著好于其他同类的不使用 OOD exposure 的方法,而 GNNSafe++ 取得了最好的性能。特别的,相比 SOTA 方法,在 Twitch 和 Cora-Structure 数据集,GNNSafe++ 对 AUROC 指标分别提升了 12.8% 和 17.0%,而对 FPR95 指标分别降低了 44.8% 和 21.0%。
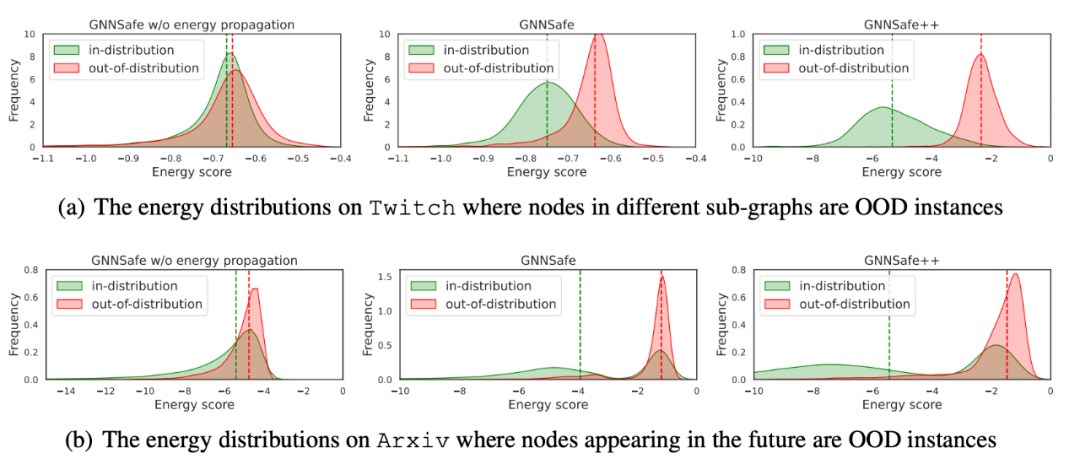
为了进一步验证提出方法的有效性,我们也对两个关键模块能量信任传播和能量正则项进行了消融实验。下图分别绘制了三种方法在 Twitch 和 Arxiv 上对 IND-Te 和OOD-Te 所估计的能量值分布。可以看到,相比于 GNNSafe w/o energy propagation(不考虑能量信任传播和能量正则项)和 GNNSafe(仅不考虑能量正则项),GNNSafe++ 所给出的能量分布能够更明显的把分布内和分布外的样本区分开。
此外,我们也探索了使用 GNN backbone 对模型性能的影响,下图分别考虑 MLP,GCN,GAT,JKNet 和 MixHop 作为主干,可以看到几种方法的相对优劣保持一致,这也进一步验证了 GNNSafe 在使用不同 GNN 主干时的优越性。

04.总结与拓展性讨论
这一工作主要对图结构数据节点分布外检测的问题进行了初步探索,并提出了一种简单有效的方法叫作 GNNSafe,可以作为这一(尚未被充分探索的)研究领域的强有力的基线方法。此外,还对如何针对不同数据集在数据划分中引入相应的分布偏移作了讨论,为图数据 OOD 检测提供了 benchmarks 参考。
当然,本文的方法以及提供的代码也可以很方便的进行拓展和延伸,包括但不限于:
其他图编码器:尽管本文主要基于图神经网络 GNN 设计了一种 OOD 检测方法,该方法也适用于图 Transformer。近期有不少大图上节点级任务的Transformer 工作 [8],如何提升这一类模型的 OOD 检测/泛化能力也是值得进一步探索的。
更多样的 OOD 测试数据:本文仅考虑了测试数据中仅包含一类 OOD 数据(尽管在不同数据集 OOD 种类有所不同),实际场景中可能一个训练好的模型需要同时处理多类 OOD 数据。如何提升单一模型对于多种 OOD 数据的识别能力,是可以考虑的未来方向。
更复杂的训练场景:在本文的问题设定基础上,可以进一步考虑很多更难的设定。例如,训练数据集中混杂着 OOD 数据,在模型训练时就需要一边做识别一边对这些数据加以利用,来提升测试时 OOD 检测的能力。其次,也可以考虑训练数据不断到来的在线场景,模型需要在不同分布数据上进行连续更新。
参考文献:
[1] Qitian Wu, et al., Handling Distribution Shifts on Graphs: An Invariance Perspective, ICLR 2022.
[2] Jiaqi Ma, et al., Subgroup Generalization and Fairness of Graph Neural Networks, NeurIPS 2021.
[3] Dario Amodei et al., Concrete problems in ai safety, Arxiv 2016.
[4] Shiyu Liang et al., Enhancing the reliability of out-of-distribution image detection in neural networks, ICLR 2018.
[5] Zenan Li et al., Graphde: A generative framework for debiased learning and out-of-distribution detection on graphs, NeurIPS 2022.
[6] Will Grathwohl et al., Your classifier is secretly an energy based model and you should treat it like one, ICLR 2020.
[7] Weitang Liu et al., . Energy-based out-of-distribution detection, NeurIPS 2020.
[8] Qitian Wu, et al., NodeFormer: A Scalable Graph Structure Learning Transformer for Node Classification, NeurIPS22.
