作者 | 黄灿安
单位 | 东北大学自然语言处理实验室

# 摘要
自动语音识别(Automatic Speech Recognition,ASR)是一种将语音序列转换为对应文本序列的技术,在语音输入法、字幕生成等场景中有广泛的应用。近年来,随着深度学习的发展,基于神经网络的端到端ASR模型逐渐取代了传统的以GMM-HMM为主的统计模型,以卷积神经网络(CNN)、循环神经网络(RNN)、基于自注意力机制的Transformer为代表的模型,由于强大的序列建模能力,使ASR的准确率有了较大的提升。
今天要介绍的模型Conformer{Conformer: Convolution-augmented Transformer for Speech Recognition}是ASR领域近年来比较受关注的方法之一。通过结合自注意力机制的全局建模能力和CNN的局部建模能力,Conformer在ASR任务上超越了序列到序列任务中应用最为广泛的Transformer。最近笔者在回顾这篇论文的时候,发现有很多地方“知其然”,却“不知其所以然”,因此查阅了大量相关论文和资料,希望通过这篇文章,对Conformer的Motivation、每个模块的作用等进行全面的介绍。
笔者提炼了这篇论文的主要贡献:
(1)提出了Conformer结构,将注意力机制的全局建模能力和CNN的局部建模能力结合起来,同时发挥两者的优势。
(2)在ASR常用的数据集LibriSpeech上取得了非常好的效果,验证了Conformer的性能。加上语言模型的情况下,Conformer在两个测试集test-clean/test-other上分别取得了WER1.9%/3.9%的SOTA结果。
(3)Conformer在小模型(参数量为10M)上也取得了2.7%/6.3%的结果,从侧面显示了Conformer结构的优势。

# 语音特征提取和基于Transformer的ASR模型
# 2.1 语音特征提取
在进行语音识别的时候,最原始的输入是一个音频文件。将音频文件读取到程序后,它们是一系列离散的采样点,通常采样率是16000,即一秒钟采样16000个点,每个采样点表示该时刻声音的振幅。在这个采样率下,一条只有几秒钟的输入音频,其序列长度也会非常长,且每个采样点所包含的语音信息比较少,因此原始音频不适合直接作为模型的输入。更普遍的做法是提取具有更多信息的声学特征,常用的声学特征有滤波器组(Filter-Bank,FBank)和梅尔频率倒谱系数(Mel-frequency Cepstral Coefficient,MFCC)。以FBank特征的提取为例,对语音信号进行预处理,进行预加重、分帧、加窗等操作,最终获得FBank声学特征。其流程如下图所示。更具体的内容及代码实现,推荐大家参考这个博客 (opens new window)。最终,一段音频提取出来的FBank特征可以用形状为(帧数,FBank维度)的张量矩阵来表示。顺带提一下,Conformer使用的声学特征是维度为80的FBank特征,这也是大多数语音相关工作的常用设置。
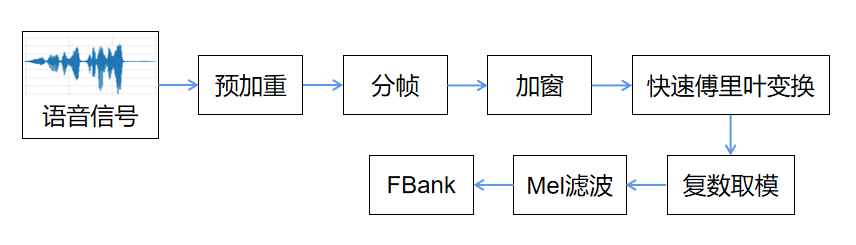
图2.1 FBank特征提取
# 2.2 基于Transformer的ASR模型
随着深度学习的发展,基于神经网络的端到端ASR模型已经成为了主流。ASR可以被看成是一种序列到序列任务,输入一段声音特征序列,通过模型计算后,输出对应的文字序列信号。在端到端ASR模型中,这种序列到序列的转换不需要经过中间状态,如音素等,而直接生成输出结果。
Transformer{Attention is all you need}是Google在2017年提出的序列到序列模型,它通过纯注意力的计算来建模序列,能够很好地获取长序列中远距离信息之间的依赖关系。具体来说,它会对序列中的每一个token与所有token进行注意力计算,因此其建模的范围是整段序列,所获取的是整个上下文的信息。这种远距离依赖建模的能力使得Transformer在机器翻译{Attention is all you need}等任务上取得非常不错的效果。
如图所示,基于Transformer的ASR模型,其输入是提取的FBank或MFCC语音特征。由于语音特征序列一般比较长,在送入模型之前,通常会进行两层步长为2的卷积操作,将序列变为原来的1/4长。基于Transformer的ASR模型编码器和解码器与原始Transformer没有差别,在编码器端,是一个多头注意力子层和一个前馈网络子层,它们分别进行残差连接和层标准化(LayerNorm)操作,而在解码器端则会多一个编码器-解码器多头注意力层,用于进行输入和输出之间的交互。
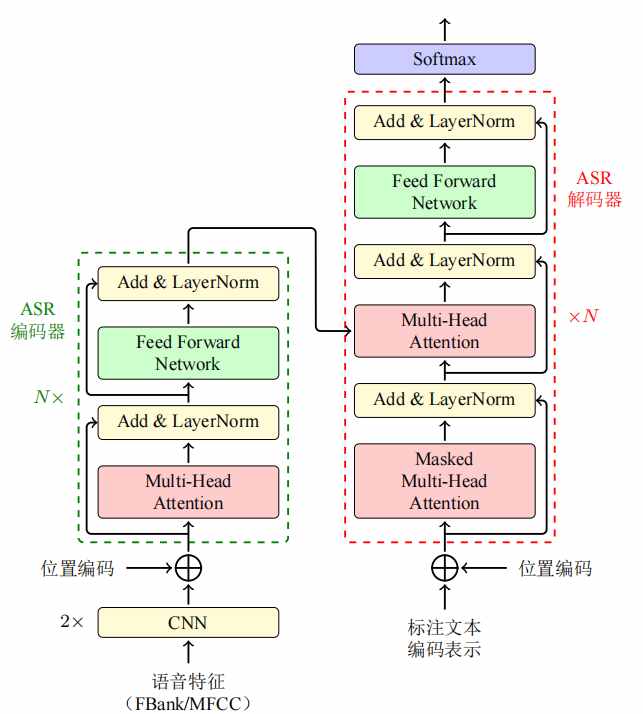
图2.2 基于Transformer的ASR模型{《机器翻译——基础与模型》}

# 论文motivation
# 3.1 基于CNN的ASR模型
除了Transformer外,也有部分工作是基于CNN来捕获局部的特征来进行语音识别,比如ContextNet{Contextnet: Improving convolutional neural networks for automatic speech recognition with global context}。由于受感受野范围的限制,CNN只能够在局部的范围内对文本进行建模,相比于RNN或Transformer,缺乏全局的文本信息。ContextNet通过引入“压缩和激发(Squeeze-and-Excitation,SE)”层{Squeeze-and-excitation networks}来获取全局特征信息。如下图所示,SE在不同特征向量之间进行全局平均池化(Global Average Pooling),然后再通过两个全连接层和sigmoid得到每个特征向量的权重,从而实现全局信息交互。然而由于只是通过平均池化和全连接来进行全局信息的交互,这种方法仍然无法很好地获取全局特征。
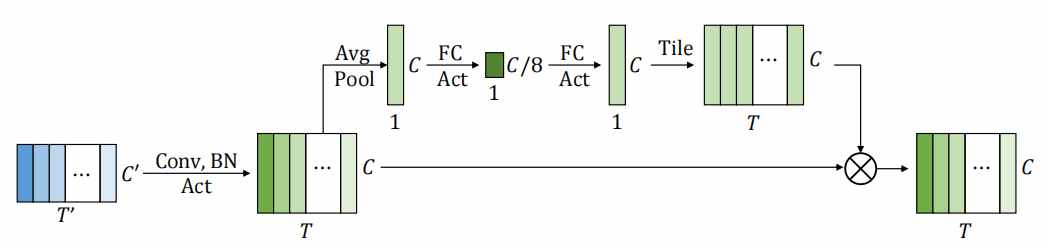
图3.1 Squeeze-and-Excitation
# 3.2 全局建模和局部建模
通过上面的介绍,我们可以看到,基于自注意力的Transformer和基于CNN的模型各有优势和不足。自注意力机制能够对全局的上下文进行建模,不擅长提取细粒度的局部特征模式;而CNN则相反。作者认为,对于ASR任务来说,全局特征和局部特征都在语音序列的建模中起到关键的作用。全局特征的作用比较好理解,因为语音序列和文本序列一样,其语义信息也会受到上下文的影响,比方说,在中文的语音识别里,可能会出现相同的音节对应多个不同的字(词),如“他”“她”和“它”、“矿工”和“旷工”、“记忆”和“技艺”等,这时候就需要包含上下文信息的全局特征来进行消歧。局部特征的作用则体现为,一个发音单元是由多个相邻的语音帧构成的,用CNN可以捕获如发音单元边界等局部特征信息。相关工作{Attention augmented convolutional networks}已经验证了将两者结合起来的优势。

# Conformer
基于以上研究背景,Conformer将卷积模块和自注意力模块融合起来。受Lite Transformer{Lite transformer with long-short range attention}等工作的启发,Conformer通过一种“夹心式”的结构,将卷积模块和自注意力模块夹在两个前馈神经网络(FFN)中间,如图中右侧虚线框内所示。
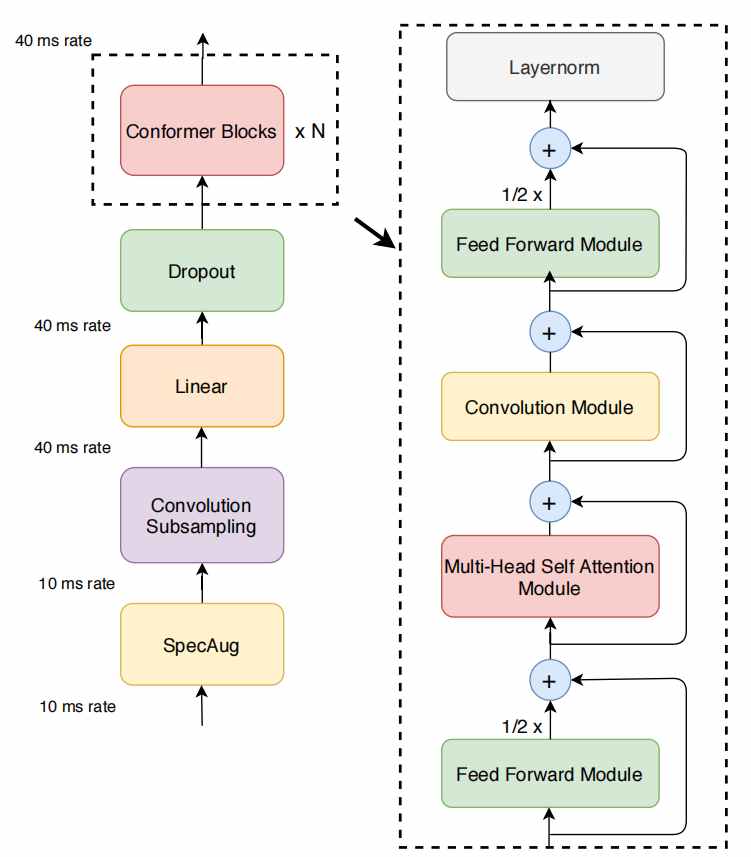
图4.1 Conformer结构
Conformer块包括四个部分:第一个前馈模块、一个多头注意力模块、一个卷积模块以及第二个前馈模块,其中每一个模块内又会有一些子模块。Conformer块的输出会最终进行LayerNorm。相比于Transformer,除了在多头自注意力之后增加卷积模块外,Conformer还进行了其它一些改进,如Pre-Norm、相对位置编码等,这些改进都对模型有很重要的影响。
# 4.1 Post-Norm和Pre-Norm
LayerNorm{Layer Normalization}是一种正则化手段,有助于训练深层模型并加速训练。根据LayerNorm在残差块中的位置不同,可以分为Post-Norm和Pre-Norm两种结构,如图{Learning Deep Transformer Models for Machine Translation}。
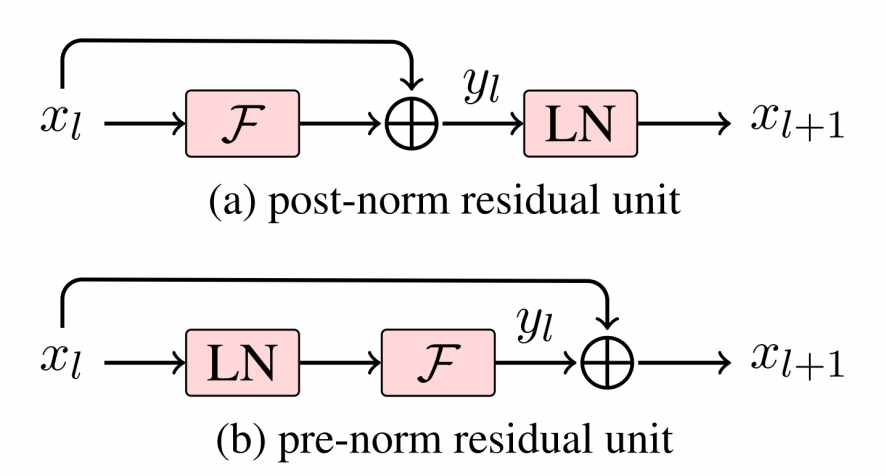
图4.2 Poat-Norm和Pre-Norm
Post-Norm是在做完残差计算之后,再对特征做LayerNorm,Transformer采用的就是这种结构;而Pre-Norm则是在残差块内,先对输入进行LayerNorm,再做计算。相关研究表明{Learning Deep Transformer Models for Machine Translation;On Layer Normalization in the Transformer Architecture},Pre-Norm可以使Transformer结构的模型堆叠更深的网络、训练更加稳定以及更快收敛。在Conformer中,每个模块都使用了Pre-Norm结构,使模型的训练更加容易。
# 4.2 多头自注意力模块

图4.3多头自注意力模块
在Transformer中,由于自注意力机制无法获取输入元素序列的顺序信息,因此引入了位置编码来作为补充。关于位置编码具体的介绍,可以参考我们公众号之前的文章{这么多位置编码方法,你都了解过么?:https://school.niutrans.com/qualityArticleInfo?id=72}。在Conformer中,多头注意力采用了相对位置编码来使得模块对不同长度的输入有更好的泛化性和鲁棒性。从后面的实验也可以看到,当去掉相对位置编码后,模型性能出现了较大的下降,说明其在Conformer中的重要性。
# 4.3 卷积模块

图4.4 卷积模块
卷积模块是Transformer中没有的模块,论文希望通过引入卷积模块来建模序列的局部特征。卷积模块使用了深度可分离卷积来建模序列,以及门控线性单元对信息进行过滤,此外还使用批量标准化(BatchNorm)和Swish激活函数来帮助训练深层模型。
# 4.3.1 深度可分离卷积
深度卷积(Depthwise-Convolution,也可以称为逐通道卷积)和逐点卷积(Pointwise-Convolution)配合起来使用,是一种用于代替传统卷积网络的高效组合方式,称为深度可分离卷积(Depthwise Separable Convolution){Xception: Deep Learning with Depthwise Separable Convolutions}。相比于传统卷积,深度可分离卷积可以有效降低网络的参数量,提高计算效率。其中,深度卷积只关注每个通道内序列之间的依赖关系,不关注不同通道之间的依赖;而逐点卷积关注了不同通道之间的依赖关系,不关注通道内的依赖。将这两种卷积组合起来,可以在较少参数量下,实现传统卷积的效果。
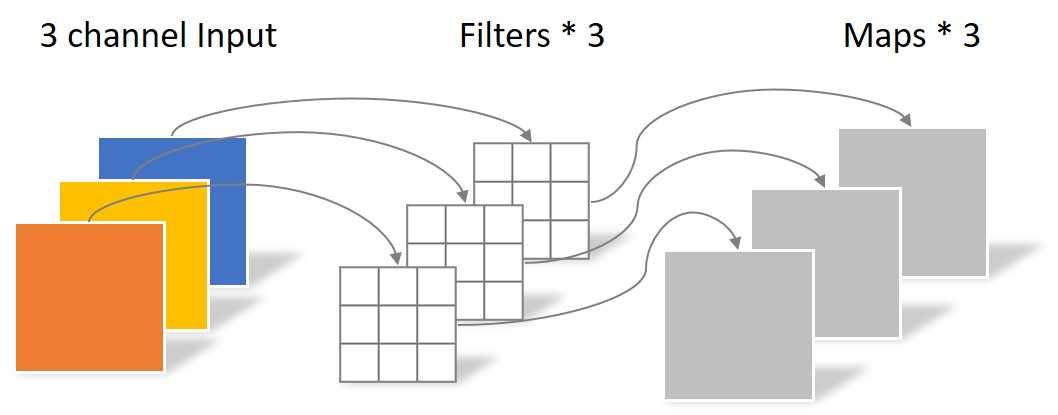
图4.5(a)深度卷积
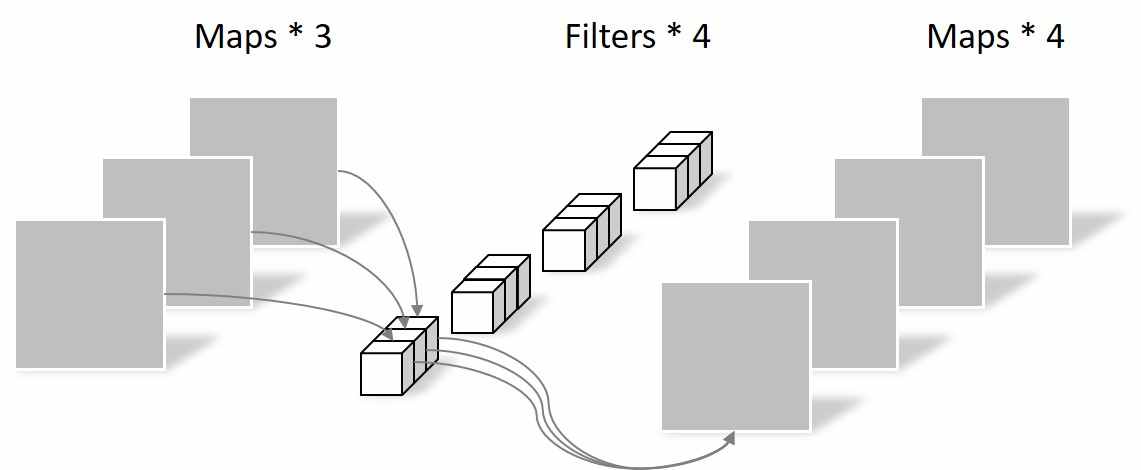
图4.5(b)逐点卷积
(以上两图来源于博客{https://yinguobing.com/separable-convolution/#fn2})
# 4.3.2 门控线性单元
门控线性单元(Gated Linear Unit,GLU)是一个基于CNN的门控机制{Language Modeling with Gated Convolutional Networks},可以缓解梯度消失现象,加速模型收敛。如图所示,GLU将输入分别经过两个卷积变换,其中一个经过变换之后再通过非线性函数sigmoid,作为门控单元来对输出进行控制。其输出公式如下所示。
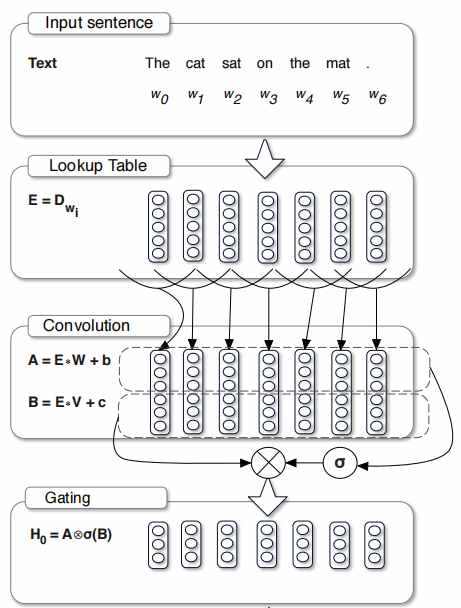
图4.6 GLU示意图
在RNN中,信息会随着序列的变长而逐渐丢失,因此需要门控机制来筛选信息,使有用的信息得以保留并往下传递。GLU的门控机制也有类似的作用,可以对特征进行筛选,使有用的特征传递到下一层,因此有利于CNN对语言进行逐层建模{Language Modeling with Gated Convolutional Networks}。Conformer利用GLU的这种语言建模能力,更好地建模局部特征。
# 4.3.3 BatchNorm
BatchNorm是基于CNN的模型常用的一种正则化手段,其有助于深层网络的训练和收敛。Conformer在卷积模块中加入BatchNorm也是为了有助于训练深层网络。
# 4.3.4 Swish激活函数
Swish函数的公式和图像如下,相比于常用的ReLU函数,其具有平滑、非单调的特点,在深层模型上的表现要更优。论文表示,使用Swish能够使得Conformer更快地收敛。
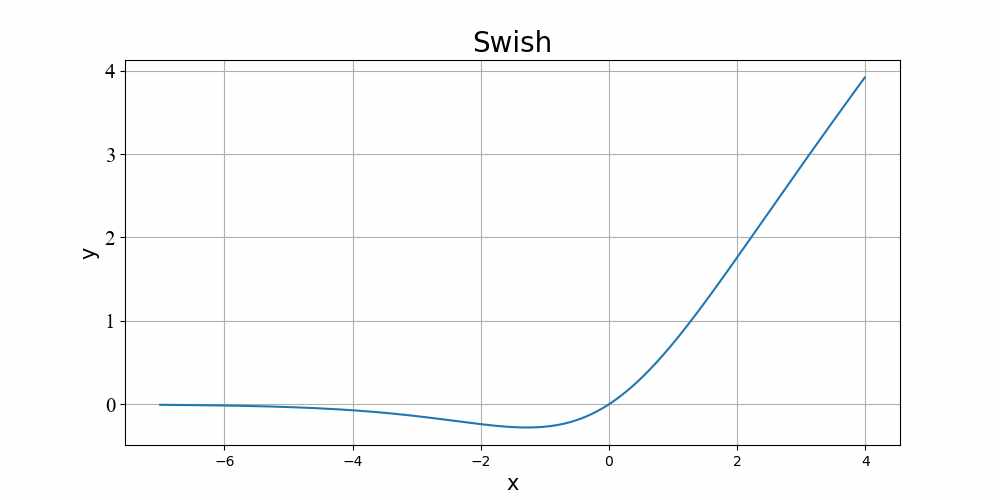
4.7 Swish函数(β=1)
# 4.4 前馈模块
前馈模块同样采取Pre-Norm结构,另外还使用了Swish作为激活函数以及dropout正则化。

图4.8 前馈模块
# 4.5 Conformer块
与Transformer块中只用一个前馈子层不同,Conformer采用一种“夹心式”的结构,将多头自注意力模块和卷积模块夹在两个前馈模块中间。这种结构来源于“马卡龙式”网络(Macaron Net){Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View},将原始Transformer中的前馈子层分为两个“半步(half-step)”的前馈子层,一个在自注意力子层前面,一个在后面。Half-step的意思是,FFN子层的输出乘以系数1/2再做残差连接。Macaron-Net的提出,是从一个叫多粒子动力学系统(MPDS)的角度去分析Transformer,将Transformer看成是MPDS中一阶对流扩散方程的常微分方程求解器,将注意力子层和看成是扩散项、前馈子层看成是对流项,并用高阶的两层前馈子层代替一层前馈子层来获得更高求解精度。虽然Conformer结构与Transformer有所不同,能否用这个理论解释还有待商榷,但是从实验结果来看,使用Macaron结构也能带来一定的提升。
综上,可以将Conformer块进行形式化表示为如下公式:

其中,是输入Conformer块的特征序列,b是batch大小,l是序列长度,d是特征维度。分别经过四个模块的计算和残差连接,其中在第二个前馈模块的残差连接之后,还对输出进行LayerNorm,得到最终的输出。
纵观Conformer的整个结构,笔者认为里面并没有提出新的方法,只是将前人的方法通过一定的组合方式应用到ASR任务上。考虑到语音序列建模的特点,Conformer加入了卷积模块,利用CNN的局部建模能力来获取序列的局部特征,是取得性能提升的关键。由于卷积模块的加入,从某种程度来说加深了网络的深度,因此Conformer用了许多高效的正则化手段来对网络进行优化,使模型更容易训练和收敛。

# 实验
# 5.1数据集
论文使用LibriSpeech数据集来训练模型,提取80维的Fbank特征,帧的窗口大小是25ms,帧移是10ms。另外,论文还使用800M大小的文本数据来训练语言模型。
# 5.2实验设置
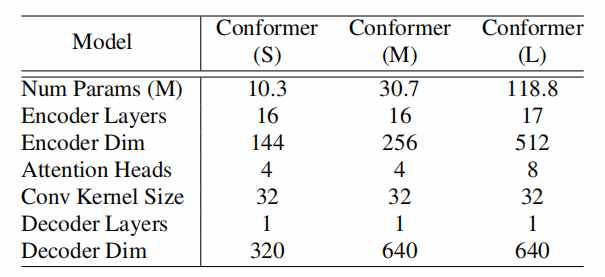
论文通过扫描不同的超参数组合(模型深度、特征维度、注意力头的数量),在不同的参数量约束下选择表现最好的组合,分别定义了S(10M)、M(30M)、L(118M)三个大小的模型。所有的模型都使用单层LSTM作为decoder。三个模型的超参数如表格所示。
# 5.3实验结果
论文比较了Conformer和其它一些模型在LibriSpeech测试集(test-clean、test-other)上的表现,比如QuartzNet(基于CNN)、ContextNet(基于CNN-encoder/RNN-decoder的CNN-RNN-Transducer)以及基于LSTM、Transformer的模型。
在不加语言模型的情况下,Conformer在各个参数量规模下都取得最好的结果;而在添加语言模型的情况下,Conformer取得了test-clean/test-other测试集WER分别为1.9%/3.9%的SOTA结果。实验结果也证明了将自注意力的全局建模能力和卷积的局部建模能力融合起来,能够更好的建模语音序列的信息。
另外,论文还分别在参数量量级10M、30M和118M大小下进行实验,在相同参数量量级下对比了前人的工作,也显示出更高的性能。而在10M参数量下的Conformer模型,性能并没有很大的下降,也取得了与其它模型可比的结果。
# 5.4消融实验
论文还做了大量的消融实验,以验证模型各个部分对性能的影响。
# 5.4.1从Conformer到Transformer
首先,论文从Conformer结构逐渐变化到Transformer结构的同时保持总的参数量不变,结果如表格所示。
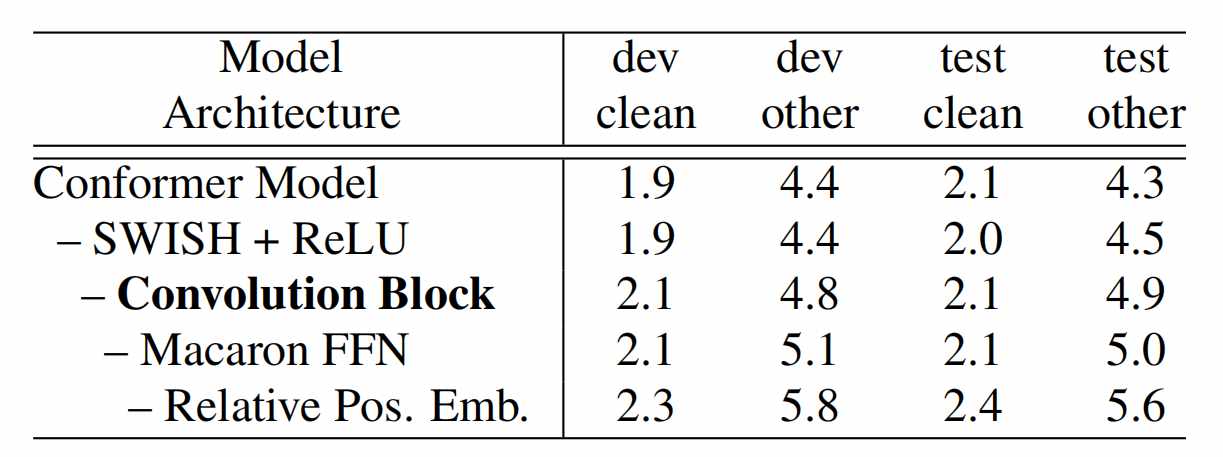
从实验结果看,去掉卷积模块和相对位置编码使得模型性能出现较大的下降,说明这两个部分在Conformer中比较重要。与卷积模块类似,相对位置编码由于只是在当前位置的附近局部范围内进行计算,也可以看成是一种局部特征的编码。该实验验证了局部特征建模有助于提升ASR模型的性能。
# 5.4.2 卷积模块
前面的实验已经验证了卷积模块在ASR任务中的作用,随之而来的一个问题就是如何将卷积模块和注意力模块结合起来。论文尝试了不同的方式来融合:
(1)使用轻量卷积{Pay less attention with lightweight and dynamic convolutions}来代替深层卷积(轻量卷积通过共享部分卷积核的权重,减少模型参数);
(2)将卷积模块放在自注意力模块之前;
(3)将输入切成多个分支,分别送入多头注意力和卷积子层并行计算,再将各自的输出拼接起来;
实验结果如表所示,所有实验结果均有细微的下降。造成结果下降的其中一个原因可能是,其它的方式比如共享权重、并行计算等,虽然说降低了模型的参数量及提升了模型效率,但是都不同程度削弱了卷积模块的局部建模能力,因此对最终结果造成影响。

# 5.4.3马卡龙式结构
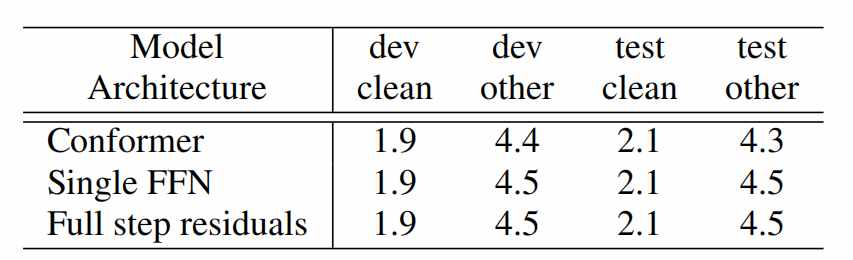
论文分别将Conformer中马卡龙式结构的两个前馈模块分别替换成:
(1)单个FFN前馈网络;
(2)Full-step的残差连接(FFN的输出不用乘以系数1/2);
替换后的模型在dev-other和test-other均出现了同样的下降。
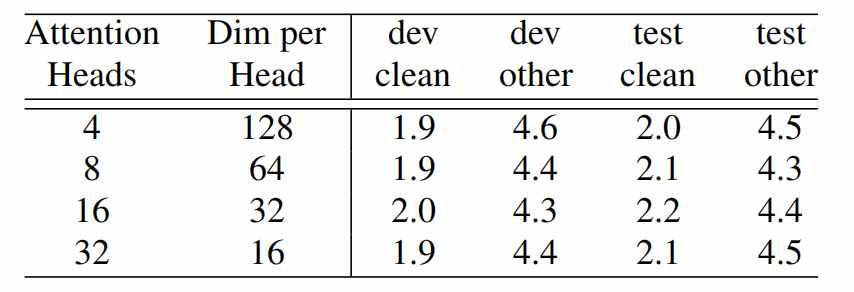
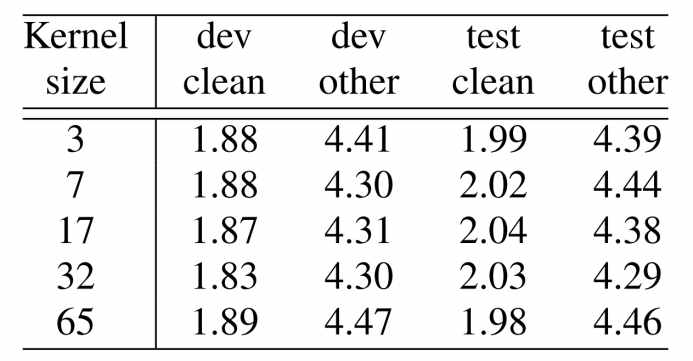
# 5.4.4注意力头和卷积核大小
论文还测试了不同注意力头的数量和卷积核大小的效果。

# 总结
Conformer在Transformer的基础上,引入了卷积模块来对局部特征进行建模,结合自注意力机制的全局建模优势和CNN的局部建模优势,在ASR任务上取得了非常优异的效果。Conformer的高性能,证明了局部特征在ASR任务中的重要作用。Conformer已经成为除了Transformer外,应用最广泛的ASR模型之一。